I. Case Study Overview
Case study on AMD’s use of IC Manage Holodeck high speed I/O scale out for a cloud bursting enablement approach to achieve compute resource scaling on Amazon AWS. This overview covers key highlights from Simon Burke’s presentation at the AWS re:Invent conference, including examples with Synopsys PrimeTime and VCS.
II. AMD’s Cloud Bursting Approach
Today’s FPGAs are truly programmable systems on a chip — there are have GPUs CPUs, hardened DDR controllers, hardened IPs, and networks on a chip. For these complex systems, as AMD’s design teams get close to tape out, they often must do additional verifications runs that they didn’t plan for.
AMD uses a cloud bursting model to burst overflow into the cloud on peak hardware that same day.
Simon Burke discussed AMD’s scale out execution of compute intensive flows and cloud enablement of EDA tools.

III. Cloud Bursting Merits

Moving to the cloud gives AMD on-demand scalability. For example, close to tape out, they often must do additional unplanned verifications runs. With cloud bursting, Simon said they can get the necessary resources to meet that demand on the same day.
With on-premise servers, while AMD could get peak licenses from our EDA vendors on premise the same day, they couldn’t get additional machines to run them on. It could easily take two to four months to get the right batch of servers configured and ready to run a job. Further, the type of server they need can be different – some need CPUs and some need lots of memory.
In addition to the extra hardware resources, Simon indicated that cloud computers are also generally better than what AMD can buy on prem. On-prem servers have a lifetime of two to four years. A3 year old server is simply slower than a one-year-old server.
IV. Cloud Bursting Challenges
Simon stated that AMD’s experience is that data security on the cloud is as good or better than on prem. Even so, there is often a perception among engineers that it’s not secure once the data is no longer on-premise. They needed to address that concern.
Additionally, their design flow must work in the cloud just the same way as it works on prem to avoid caching issues. Thus, AMD needed to make their cloud environment similar to their on-prem environment, including ensuring data storage compatibility. Amazon’s three storage options:
EBS (Elastic Block Store)
Reasonably fast, but it is assigned to a single instance and is not shareable. So, it doesn’t look like an NFS mountable drive which is what most EDA flows expect.
EFS (Elastic File System)
EFS is shareable across multiple servers, but it has some performance challenges. AMD could see a significant runtime performance degradation compared to our on-prem NetApp.
FSx Lustre
Amazon has been working to address the gap between EBS and EFS with FSx Lustre. There are some trade-offs there in terms of how you enable it, but it may potentially address some of the technical issues.
V. IC Manage Holodeck for AMD’s Cloud Bursting & Scale Out
AMD uses IC Manage Holodeck to address many of their challenges with cloud bursting and scale out. They use Holodeck because it addresses these cloud bursting enablement aspects. Below are some of the Holodeck features Simon said they liked.

Holodeck virtually projects the NFS file systems from on-premise to the cloud in just minutes; engineers then get a real-time upload to the cloud of only the specific data needed for the job running. Holodeck then deletes the cloud data when the job is complete.

Because Holodeck uploads only the data needed for the job, it’s fast. It’s also on-demand, so when someone requests a block, it gets copied from AMD prem into a local cache and gets served to the application.

Holodeck uses block-based storage, not file based, which makes a big difference for performance EDA flows.
EDA flows tend to read small sections of large files quite often. This means that Holodeck only copies the block it is reading, as opposed to the entire file.

IC Manage Holodeck uses NVMe drives for its caching mechanism. Because most of the Amazon ECS EC2 instances already have extremely fast NVMe drives on them, AMD does not need to pay for additional storage.
Holodeck Handles the different I/O profiles and requirement for both of AMD’s storage types: large semi static read data, and small dynamic workspace data.
![]()
Holodeck’s virtual file system uploads only the exact data needed; then, when the instance goes away, or when the job finishes, the data is deleted from the cloud. This reduces cloud storage costs.
Additionally, while Amazon’s cloud is highly secure, Simon stated that it addresses some of AMD engineers’ security concerns to know that the data is no longer in the cloud once the job is complete.
VI. Cloud Bursting Architecture
Simons shared this architecture diagram to capture AMD’s approach. AMD uses a Holodeck server which looks at all NFS file systems and packages them to be sent to Amazon. They typically use NetApp for NFS file service and those feed into the Holodeck.
On the Amazon side, AMD has a Holodeck tracker, which is the first level of cache that provides the virtual file systems. The second level runs on the computer instance itself, using the NVMe disks as a cache – this exposes the file systems, so they look like they’re an NFS mounted file.
AMD also uses IC Manage as its database server, so AMD has a proxy server there to do some caching to offload any network issues between AMD and Amazon. There is some variability, so Simon shared that it’s good to manage some of that with caches.
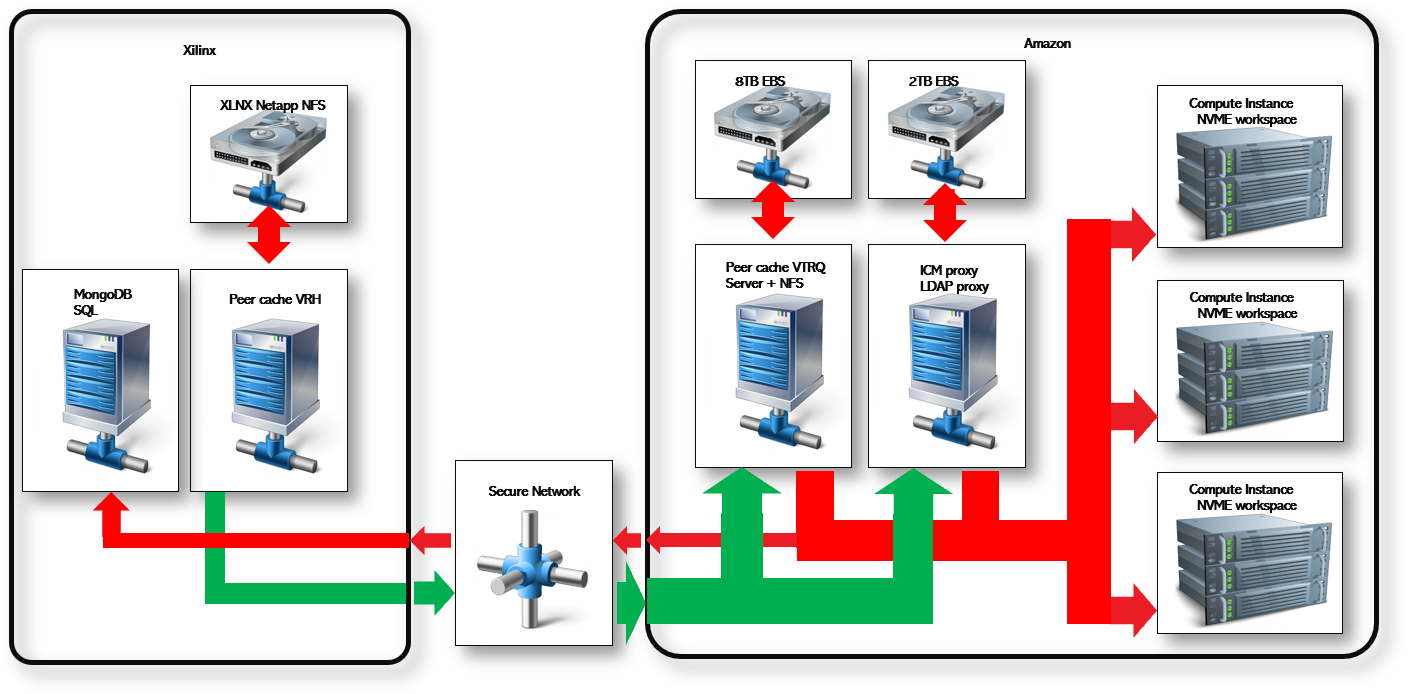
Click to enlarge
VII. Results: PrimeTime Runtime Acceleration in the Cloud
Simon commented that timing capture within AMD is not the traditional STA run that is typical in an ASIC world. It’s more like critical path analysis. AMD must capture the delays on a number of net segments and feed them into their database, so they must do a lot more runs.

Simon commented that the data for this approach with Synopsys Primetime made it clear it runs “screamingly fast” on Amazon. What would take AMD 61 hours to run on prem they can in 34 hours on Amazon — almost a 2x speed-up.
He noted that for AMD’s test cases, they generally do not run the entire chip because it won’t fit in the memory footprint and cloud vendors tend not to have very fast large memory machines. So, they prune out just the parts they care about until they fit in the memory footprint — and run that on the cloud as a more efficient way of running on a cloud server.
VIII. Conclusion: AMD’s production cloud bursting
According to Simon, AMD is currently supporting VCS verification flow in burst mode on AWS as a production flow — that is what peaks on their queue most often.
The timing flow with Primetime that he showed was proof of concept, and not yet a production flow. His goal is to be able to take an on-prem flow and run it on the cloud without significant changes to the flow. When they transition and run a flow, they do still have to modify the environment a little bit to make it work.
Simon stated that VCS is already in production, as it’s not a huge effort for AMD to transition running on the cloud with their current environment.